I have been making hot takes and hypothesizing about so many things to my friends, and to some extent I have always been too lazy to put together a proper writeup. Hopefully in the coming days, I will turn more of these scattered ideas into structured posts, not because every hypothesis will be right, but because writing forces clarity, and clarity is the first step toward testing whether an idea actually holds up. And if any of these ideas spark something for you (agreement, disagreement, or a better hypothesis entirely), I would love to hear it. The best conversations start with a half-baked idea and a willing interlocutor. Feel free to email me your hot takes.
I have not done any experiment on it nor I have compute to do it.
Should we show a language model the Navier-Stokes equations before it learns to add fractions?
TLDR Hypothesis: LLM training should follow the Chomsky hierarchy as a curriculum, progressing from simple pattern recognition (Type 3) up to undecidable complexity (Type 0+). Each phase builds on the previous one, mirroring how humans learn: first speak, then memorize, then calculate, then reason, then develop judgment.
As per GPT-3 Figure 1.1, stochastic gradient descent trains on IID data, learning horizontally across the distribution and at sufficient scale, a meta-loop (The Magic! aka scaling hypothesis) emerges that enables vertical extraction (non IID knowledge) via in-context learning. However, I argue/hypothesize that imposing curriculum order is a better prior than relying on scale alone to discover structure.
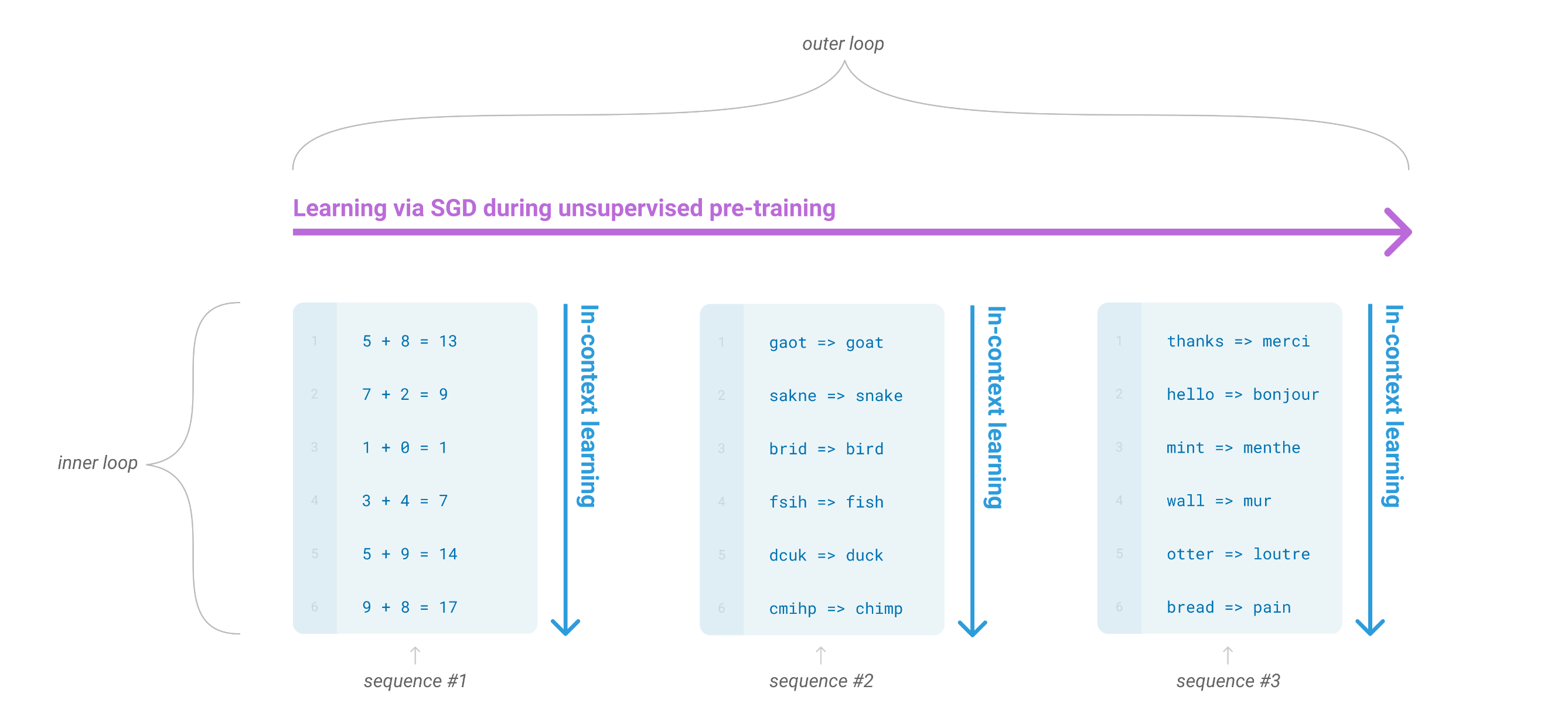 Figure 1: Language model meta-learning (from GPT-3 paper).
Figure 1: Language model meta-learning (from GPT-3 paper).
The Bitter Lesson
The Bitter Lesson of data mix would say: stop hand-crafting curricula, just scale IID data and let the model figure it out. And to be fair, scaling IID is a strong baseline. The Scaling Hypothesis of GPT-3 argued that unordered data at sufficient scale lets structure emerge for free via in-context learning. But I hypothesize that ordering data along the Chomsky ladder could outperform this strong baseline. Teams spend months hand-tuning data ratios (40% web, 15% code, 10% math) searching for the perfect blend. But perhaps the same data, shown in the right order, would outperform/improve any static mix. The structure isn’t ONLY in what you show, it’s ALSO in when you show it.
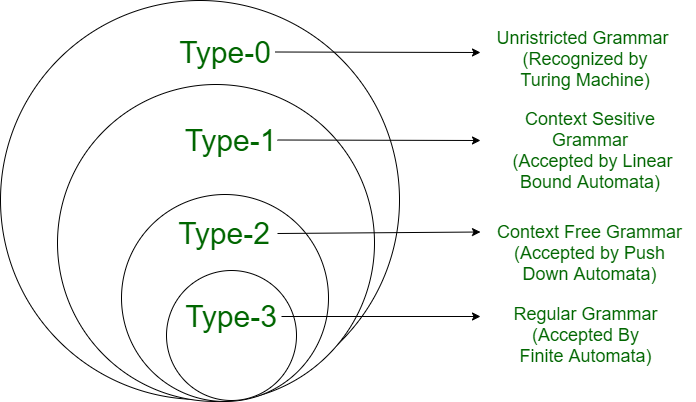 Figure 2: Chomsky hierarchy of languages. Source
Figure 2: Chomsky hierarchy of languages. Source
Example
Note: The Chomsky type labels below are used hypothetically to describe the complexity of training data in the context of LLM curriculum learning, not as formal grammar-theoretic classifications. For instance, a list of primes is not literally a regular language (Type 3), but it represents the kind of shallow pattern-level data a model would encounter in the earliest training phase. The analogy maps data complexity to the Chomsky ladder, not the formal language class itself.
- Type 3: 2, 3, 5, 7, 11, 13, 17, 19, 23, 29…
- Type 2: A prime number is a number greater than 1 divisible only by 1 and itself, like 7.
- Type 1: Is 91 prime? 91 / 7 = 13, so 91 = 7 × 13, therefore 91 is not prime.
- Type 0: There are infinitely many primes: if you multiply all known primes and add 1, the result must have a new prime factor, contradiction.
- Type 0+: Are there infinitely many twin primes like (11, 13) and (17, 19)?
Hypothesis: The Chomsky hierarchy ranks languages from simple patterns (Type 3) to undecidable complexity (Type 0 and beyond), and LLM training should follow this same ladder. You start with massive raw text so the model learns basic grammar and syntax (Type 3 -> 2), then introduce factual and context-dependent knowledge (Type 2 -> 1), then teach formal mathematical and symbolic manipulation (Type 1), then train explicit multi-step reasoning chains that approach general computation (Type 0), and finally polish with hard tasks and human preference alignment (Type 0 and beyond). Each phase depends on the one before it because you cannot reason about what you do not know, and you cannot know what you cannot linguistically represent. This mirrors how humans learn: first we speak, then we memorize, then we calculate, then we reason, then we develop judgment. The hierarchy is not just a classification of grammars but a blueprint for building intelligence layer by layer.
Proposed Hypothetical Order
Phase 1: Language Foundation (Type 3 -> 2)
- What: Teach the model how language looks and flows
- Data: Raw web text, books, GitHub code, forums
- Learns: Grammar, syntax, nesting, token patterns, code structure
- Analogy: A child learning to speak before understanding the world
Phase 2: Knowledge Grounding (Type 2 -> 1)
- What: Teach the model what is true about the world
- Data: Wikipedia, encyclopedias, textbooks, factual QA, API docs
- Learns: Facts, relationships, conditional truths, type systems
- Analogy: A student reading encyclopedias and memorizing facts
Phase 3: Structured Math & Formal Operations (Type 2 -> 1)
- What: Teach the model to manipulate symbols and solve formally
- Data: Math textbooks, solved problems, LeetCode, algorithm books
- Learns: Arithmetic, algebra, proofs, complexity analysis, data structures
- Analogy: A student learning to solve equations and write algorithms
Phase 4: Reasoning Chains (Type 1 -> 0)
- What: Teach the model to chain skills into multi-step thinking
- Data: Chain-of-thought demos, debug traces, logic puzzles, planning tasks
- Learns: Step-by-step reasoning, planning, self-correction, backtracking
- Analogy: A student learning to show their work and think out loud
Phase 5: Hard Tasks & Alignment (Type 0+)
- What: Push boundaries and align with human judgment
- Data: RLHF/DPO preference pairs, olympiad math, competitive programming, adversarial problems
- Learns: Expert-level problem solving, safety, helpfulness, nuance
- Analogy: A professional being mentored by senior experts
Detailed Breakdown by Category
| Category | Phase | Chomsky Type | What It Looks Like |
|---|---|---|---|
| Knowledge | Phase 1 | Type 3 | Surface co-occurrences: Einstein near physics near Germany |
| Knowledge | Phase 2 | Type 2 | Structured facts: Einstein developed general relativity in 1915 |
| Knowledge | Phase 3 | Type 1 | Formal definitions: A prime number is divisible only by 1 and itself |
| Knowledge | Phase 4 | Type 0 | Chained inference: Because X is true and Y follows from X, therefore Z |
| Knowledge | Phase 5 | Type 0+ | Nuanced judgment: This is debated, here are both sides with evidence |
| Math | Phase 1 | Type 3 | Number formats and digit patterns and LaTeX tokens appearing in text |
| Math | Phase 2 | Type 2 | The Pythagorean theorem states a² + b² = c² (fact, not operation) |
| Math | Phase 3 | Type 1 | Solve 2x + 3 = 7, so x = 2 (step-by-step manipulation) |
| Math | Phase 4 | Type 0 | Prove by induction: step 1 is base case, step 2 is inductive step, QED |
| Math | Phase 5 | Type 0+ | Olympiad problems requiring creative insight and novel technique combinations |
| Reasoning | Phase 1 | Type 3 | Implicit logical patterns in text: “because”, “therefore”, “however” |
| Reasoning | Phase 2 | Type 2 | Simple if-then: If it rains, the ground is wet |
| Reasoning | Phase 3 | Type 1 | Formal logic: Given A -> B and B -> C, conclude A -> C |
| Reasoning | Phase 4 | Type 0 | Full CoT: Let me think step by step… first… then… therefore… |
| Reasoning | Phase 5 | Type 0+ | Novel analogies, creative problem framing, and handling ambiguity |
| Code | Phase 1 | Type 3 | Raw code: def hello(): print("hi"), learning syntax and patterns |
| Code | Phase 2 | Type 2 | Docs and types: “This function takes a sorted list and returns the index” |
| Code | Phase 3 | Type 1 | Algorithms: Binary search runs in O(log n), here is why and how |
| Code | Phase 4 | Type 0 | Plan -> code -> test -> debug: First design the API, then implement |
| Code | Phase 5 | Type 0+ | System design, competitive programming, and novel algorithm invention |
Hypothesized Order
- Phase 1: Learn to SPEAK (form)
- Phase 2: Learn to KNOW (content)
- Phase 3: Learn to CALCULATE (operations)
- Phase 4: Learn to REASON (process)
- Phase 5: Learn to JUDGE (wisdom)
The Irony
Chomsky famously argued that “Colorless green ideas sleep furiously” is grammatical but meaningless, and “Furiously sleep ideas green colorless” is neither grammatical nor meaningful, yet both are equally improbable statistically. His point: grammaticality cannot be identified with statistical probability. A sentence can be perfectly grammatical yet have zero probability in any corpus. He spent decades insisting that language is a rule-based faculty of the mind, not a pattern in data, and that statistical models of language are not models of language at all.
And here I am, using the man’s own hierarchy as a training schedule for the very statistical models he spent his career rejecting. Sorry, Professor. 🫡
Credit: Thanks Zarzis for introducing me to Chomsky Language hierarchy.
Citation
If you find this post useful, you can cite it as:
@article{bari2026chomskycurriculum,
title = {On the Connection of Chomsky Hierarchy of Languages vs Data Curriculum Learning in LLMs},
author = {Bari, M Saiful},
year = {2026},
month = {March},
url = {https://sbmaruf.github.io/post/chomsky/}
}