Abstract
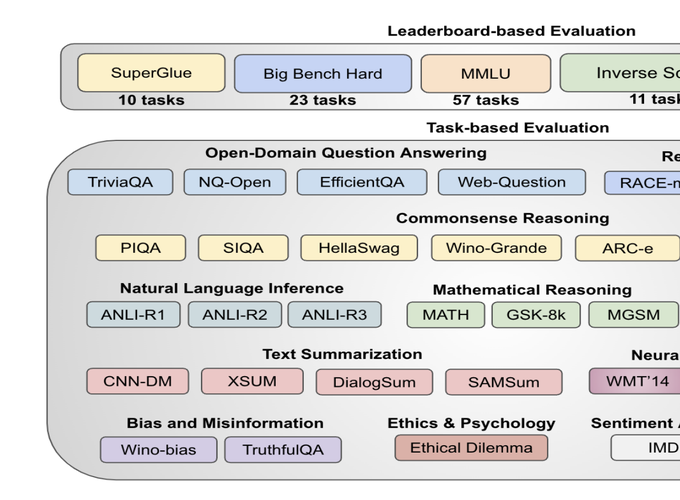
The development of large language models (LLMs) such as ChatGPT has brought a lot of attention recently. However, their evaluation in the benchmark academic datasets remains under-explored due to the difficulty of evaluating the generative outputs produced by this model against the ground truth. In this paper, we aim to present a thorough evaluation of ChatGPT’s performance on diverse academic datasets, covering tasks like question-answering, text summarization, code generation, commonsense reasoning, mathematical problem-solving, machine translation, bias detection, and ethical considerations. Specifically, we evaluate ChatGPT across 140 tasks and analyze 255K responses it generates in these datasets. This makes our work the largest evaluation of ChatGPT in NLP benchmarks. In short, our study aims to validate the strengths and weaknesses of ChatGPT in various tasks and provide insights for future research using LLMs. We also report a new emergent ability to follow multi-query instructions that we mostly found in ChatGPT and other instruction-tuned models. Our extensive evaluation shows that even though ChatGPT is capable of performing a wide variety of tasks, and may obtain impressive performance in several benchmark datasets, it is still far from achieving the ability to reliably solve many challenging tasks. By providing a thorough assessment of ChatGPT’s performance across diverse NLP tasks, this paper sets the stage for a targeted deployment of ChatGPT-like LLMs in real-world applications.