2024
The ChatGPT moment: The past, current and future (potential) of LLMs
The talk summarizes how ChatGPT’s release marked a turning point in Generative AI, driven by refined integration of traditional …
2023
Pathways to semi-(un)supervised* NLP Brain
This talk discusses the evolving field of transfer learning, from LSTMs to large language models, and shows new direction on the …
2022
2021
Finetuned Language Models Are Zero-Shot Learners
This talk summarizes the paper
Finetuned Language Models Are Zero-Shot Learners.
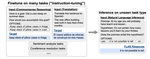
GPT-3: Language Models are Few-Shot Learners
This talk summarizes the paper
Language Models are Few-Shot Learners.

2020
mBART: pretraining seq2seq architecture
This talk summarizes the paper
mBART and some pretraining concepts.
2019

Transforme-XL
This talk summarizes the paper
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context. It assumes that audience are …

2018
Iterated Dilated Convolutions for NLP - NER as an example
This talk summarizes the paper
Fast and Accurate Entity Recognition with Iterated Dilated Convolutions.

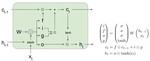
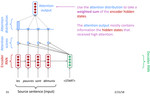
Attention Mechanism
This talk summarizes the paper
Effective Approaches to Attention-based Neural Machine Translation.
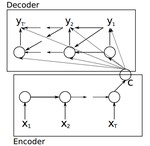
Encode Decode Architecture
This talk summarizes the paper
Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation.