Stop Taking Tokenizers for Granted: They Are Core Design Decisions in Large Language Models
Reframing tokenization as a core modeling decision in LLMs rather than a preprocessing step, arguing for context-aware tokenizer and model co-design.
Amazon Nova 2: Multimodal Reasoning and Generation Models
A family of multimodal reasoning and generation models from Amazon AGI.
ZeroSumEval: An Extensible Framework for Scaling LLM Evaluation with Inter-Model Competition
An extensible framework for scaling LLM evaluation through inter-model competition.
ALLaM: Large Language Models for Arabic and English
A sovereign bilingual LLM for Arabic and English, achieving state-of-the-art Arabic performance, integrated into IBM Watsonx and Microsoft Azure.
Humanity's Last Exam
A large-scale collaborative benchmark designed to test the limits of frontier AI systems.
Beyond Fertility: STRR as a Metric for Multilingual Tokenization Evaluation
A new metric for multilingual tokenization evaluation that goes beyond fertility-based measures.
A Systematic Survey and Critical Review on Evaluating Large Language Models: Challenges, Limitations, and Recommendations
A systematic survey and critical review on evaluating large language models with recommendations for more rigorous evaluation.
When Benchmarks are Targets: Revealing the Sensitivity of Large Language Model Leaderboards
Revealing the sensitivity of LLM leaderboards to evaluation choices, showing that rankings can shift significantly with minor methodological changes.
BenLLM-Eval: A Comprehensive Evaluation into the Potentials and Pitfalls of Large Language Models on Bengali NLP
Comprehensive evaluation of LLMs on Bengali NLP, examining potentials and pitfalls for low-resource language processing.
Transfer Learning for Language Model Adaptation
PhD thesis on transfer learning for language model adaptation, covering multilingual generalization and scalable training dynamics.
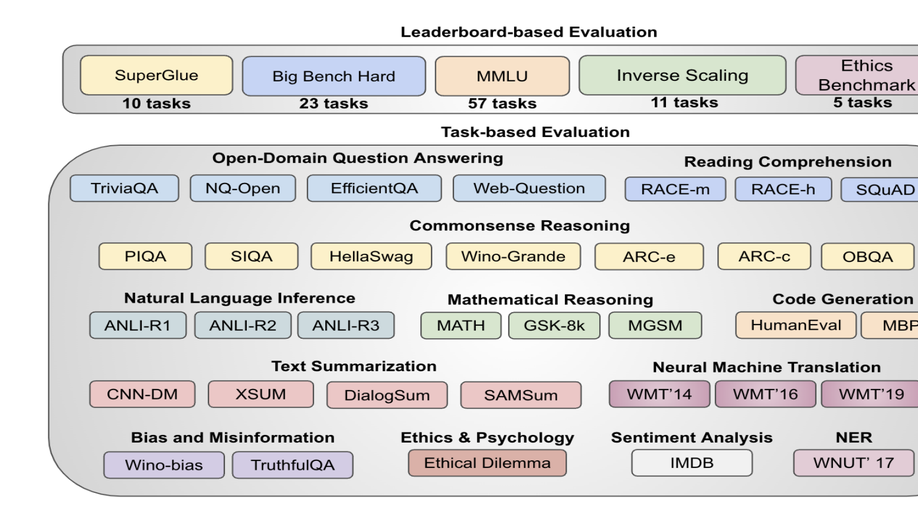
A Systematic Study and Comprehensive Evaluation of ChatGPT on Benchmark Datasets
The paper comprehensively evaluates ChatGPT’s performance on various academic tasks, covering 140 tasks across diverse fields, highlighting strengths and weaknesses, and introducing a new ability to follow multi-query instructions, ultimately paving the way for practical applications of ChatGPT-like models.
BLOOM+1: Adding Language Support to BLOOM for Zero-Shot Prompting
Adding new language support to the BLOOM multilingual language model for zero-shot prompting.
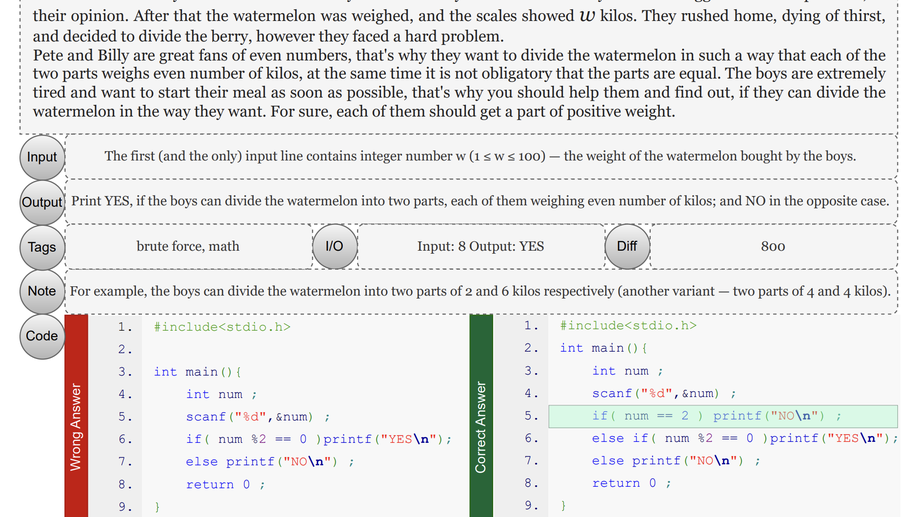
xCodeEval: A Large Scale Multilingual Multitask Benchmark for Code Understanding, Generation, Translation and Retrieval
We introduce xCodeEval, the largest executable multilingual multitask benchmark to date consisting of 25M document-level coding examples from about 7.5 K unique problems covering up to 17 programming languages with execution-level parallelism.
Crosslingual Generalization through Multitask Finetuning
Shows multitask multilingual generalization in language model.
What Language Model to Train if You Have One Million GPU Hours?
Investigating scaling laws and practical guidance for training language models under constrained compute budgets.
SPT: Semi-Parametric Prompt Tuning for Multitask Prompted Learning
A semi-parametric prompt tuning method improving multitask generalization for parameter-efficient fine-tuning with cross-task zero-shot generalization.
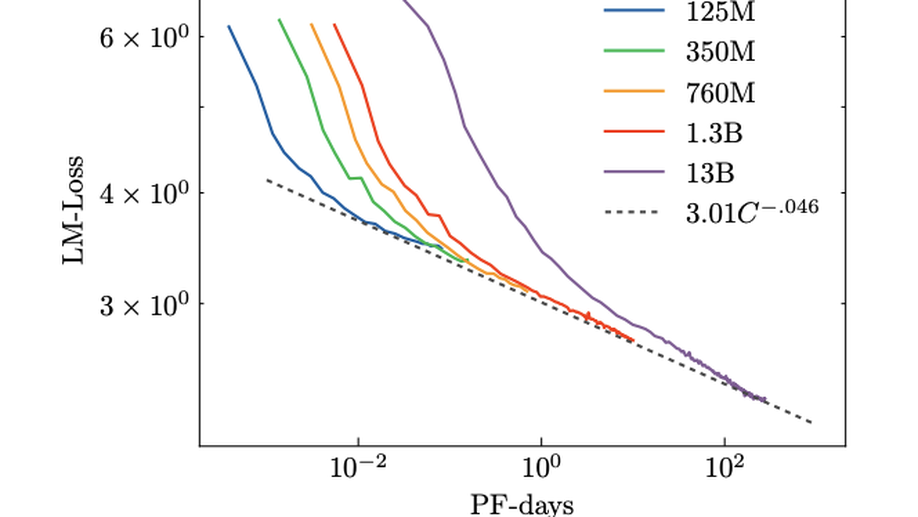
What Language Model to Train if You Have One Million GPU Hours?
The crystallization of modeling methods around the Transformer architecture has been a boon for practitioners. Simple, well-motivated architectural variations that transfer across tasks and scale, increasing the impact of modeling research. However, with the emergence of state-of-the-art 100B+ parameters models, large language models are increasingly expensive to accurately design and train. Notably, it can be difficult to evaluate how modeling decisions may impact emergent capabilities, given that these capabilities arise mainly from sheer scale.Targeting a multilingual language model in the 100B+ parameters scale, our goal is to identify an architecture and training setup that makes the best use of our 1,000,000 A100-GPU-hours budget. Specifically, we perform an ablation study comparing different modeling practices and their impact on zero-shot generalization. We perform all our experiments on 1.3B models, providing a compromise between compute costs and the likelihood that our conclusions will hold for the target 100B+ model. In addition, we study the impact of various popular pretraining corpora on zero-shot generalization. We also study the performance of a multilingual model and how it compares to the English-only one. Finally, we consider the scaling behaviour of Transformers to chose the target model size, shape, and training setup.
PromptSource: An Integrated Development Environment and Repository for Natural Language Prompts
Over 2,000 prompts for roughly 170 datasets are available through PromptSource framework.
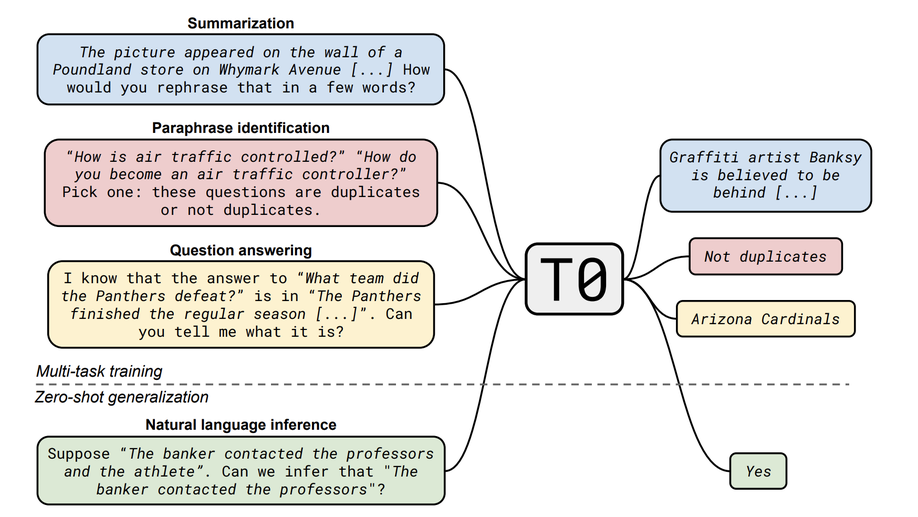
Multitask Prompted Training Enables Zero-Shot Task Generalization
T0 shows zero-shot task generalization on English natural language prompts, outperforming GPT-3 on many tasks, while being 16x smaller!
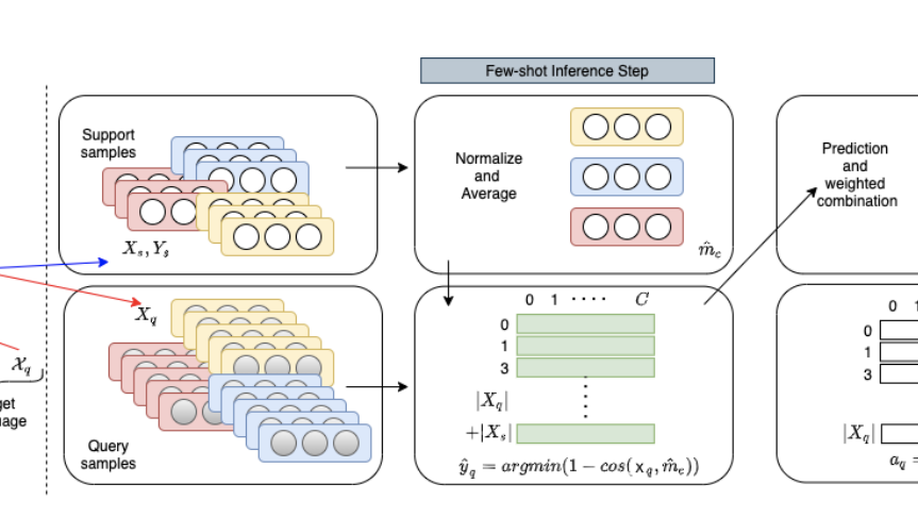
Nearest Neighbour Few-Shot Learning for Cross-lingual Classification
We propose a trasductive approach for few shot cross-lingual classification.
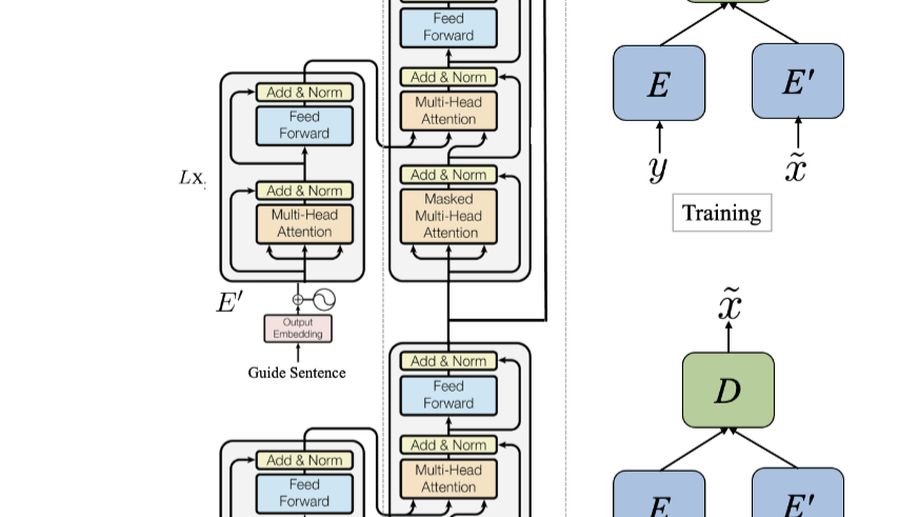
AugVic: Exploiting BiText Vicinity for Low-Resource NMT
We propose AugVic, a data augmentation framework for sequence to sequence model (i.e. NMT) using Language Model.
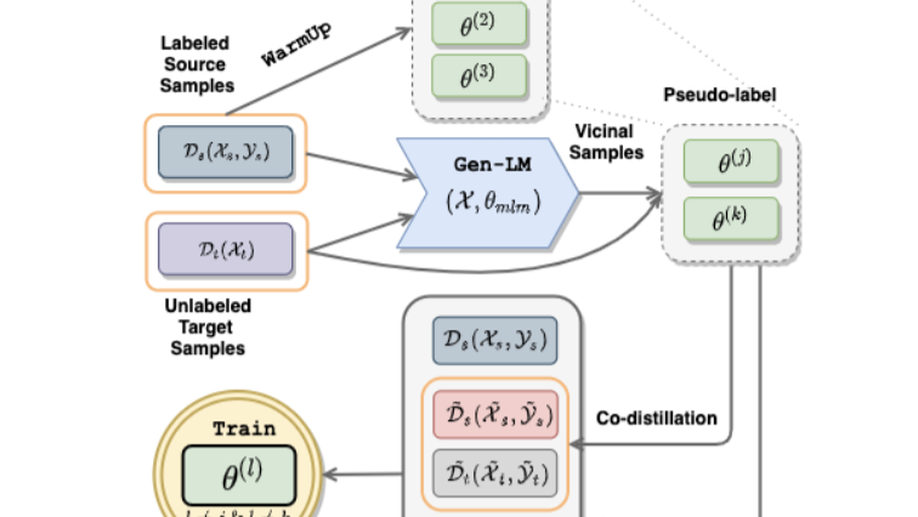
UXLA: A Robust Unsupervised Data Augmentation Framework for Zero-Resouce Cross-Lingual NLP
We propose UXLA, a novel data augmentation framework for self-supervised learning in zero-resource transfer learning scenarios.
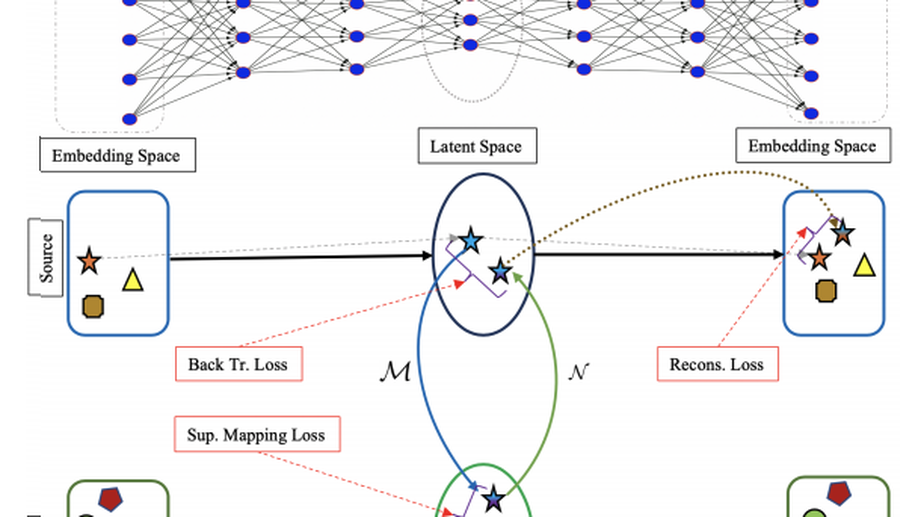
LNMAP: Departures from Isomorphic Assumption in Bilingual Lexicon Induction Through Non-Linear Mapping in Latent Space
We propose a novel semi-supervised method to learn cross-lingual word embeddings for BLI.
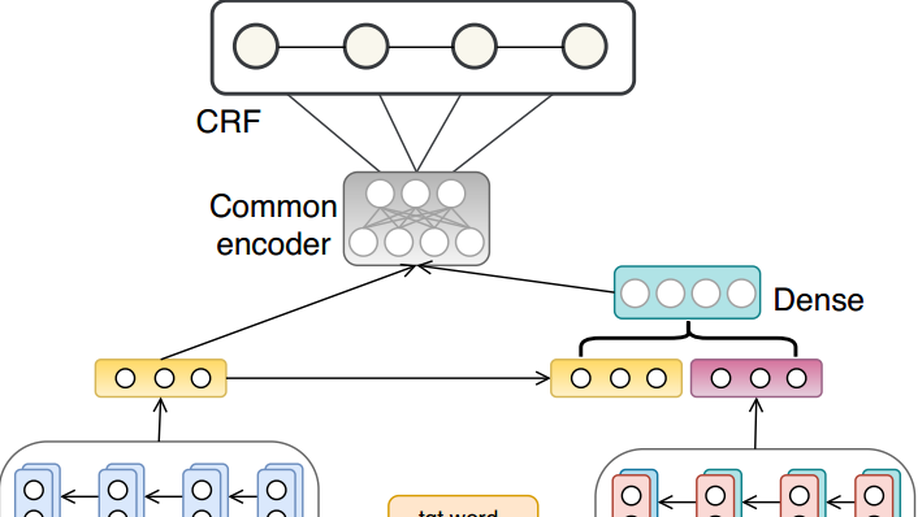
Zero-Resource Cross-Lingual Named Entity Recognition
We propose a superior model and training method for zero resource transfer of Cross-lingual Named Entity Recognition.
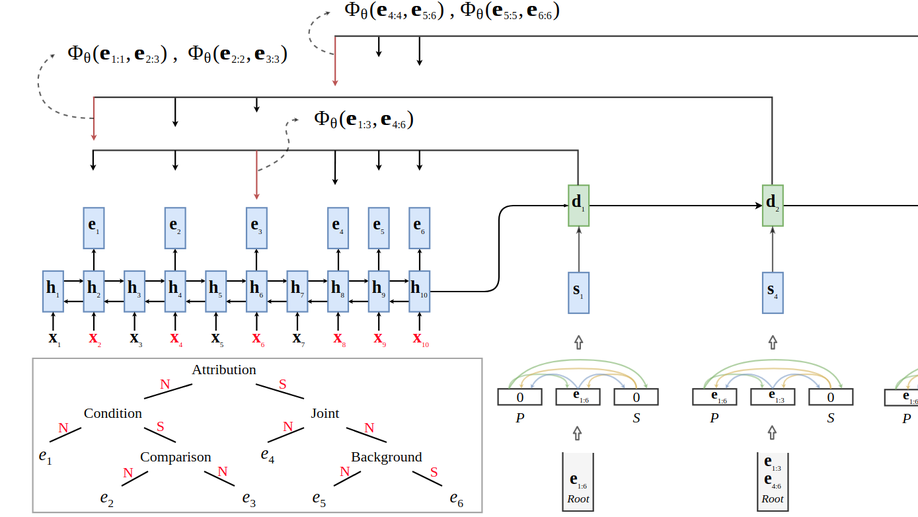
A Unified Linear-Time Framework for Sentence-Level Discourse Parsing
We propose an efficient neural framework for sentence-level discourse analysis in accordance with Rhetorical Structure Theory (RST). Our framework comprises a discourse segmenter to identify the elementary discourse units (EDU) in a text, and a discourse parser that constructs a discourse tree in a top-down fashion. Both the segmenter and the parser are based on Pointer Networks and operate in linear time. Our segmenter yields an F1 score of 95.4, and our parser achieves an F1 score of 81.7 on the aggregated labeled (relation) metric, surpassing previous approaches by a good margin and approaching human agreement on both tasks (98.3 and 83.0 F1).

Data Analytics: Concepts, Techniques and Applications
This book chapter goes through various aspects of regression and maths behind them.