AugVic: Exploiting BiText Vicinity for Low-Resource NMT
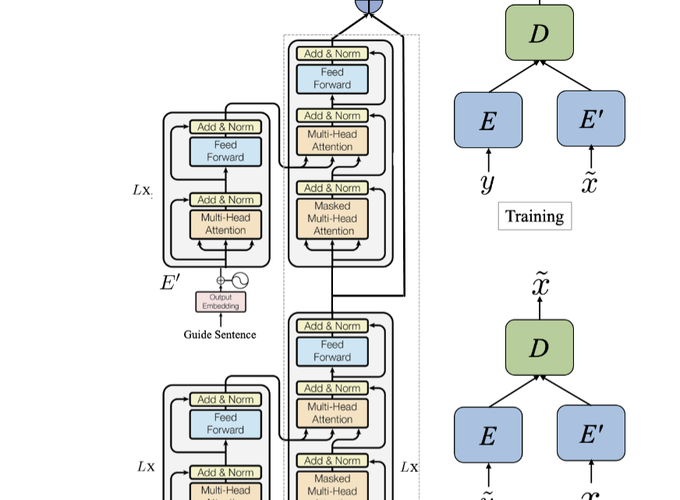 Image credit: [AugVic]
Image credit: [AugVic]
AugVic: Exploiting BiText Vicinity for Low-Resource NMT
Abstract
The success of Neural Machine Translation (NMT) largely depends on the availability of large bitext training corpora. Due to the lack of such large corpora in low-resource language pairs, NMT systems often exhibit poor performance. Extra relevant monolingual data often helps, but acquiring it could be quite expensive, especially for low-resource languages. Moreover, domain mismatch between bitext (train/test) and monolingual data might degrade the performance. To alleviate such issues, we propose AugVic, a novel data augmentation framework for low-resource NMT which exploits the vicinal samples of the given bitext without using any extra monolingual data explicitly. It can diversify the in-domain bitext data with finer level control. Through extensive experiments on four low-resource language pairs comprising data from different domains, we have shown that our method is comparable to the traditional back-translation that uses extra in-domain monolingual data. When we combine the synthetic parallel data generated from AugVic with the ones from the extra monolingual data, we achieve further improvements. We show that AugVic helps to attenuate the discrepancies between relevant and distant-domain monolingual data in traditional back-translation. To understand the contributions of different components of AugVic, we perform an in-depth framework analysis.