Nearest Neighbour Few-Shot Learning for Cross-lingual Classification
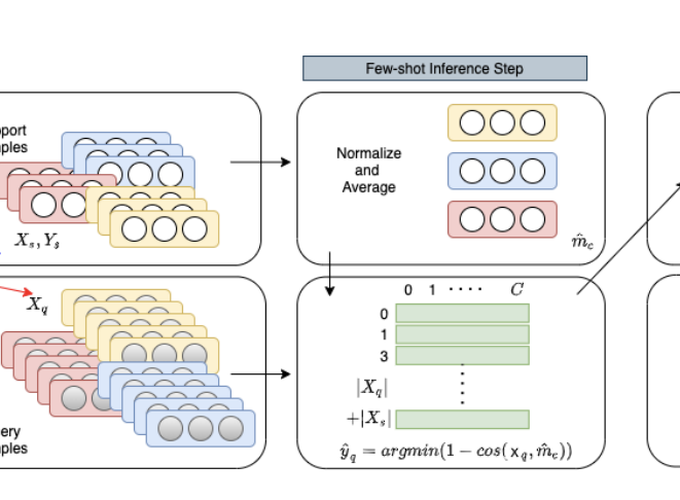 Image credit: [Augvic]()
Image credit: [Augvic]()
Nearest Neighbour Few-Shot Learning for Cross-lingual Classification
Abstract
Even though large pre-trained multilingual models (e.g. mBERT, XLM-R) have led to significant performance gains on a wide range of cross-lingual NLP tasks, success on many downstream tasks still relies on the availability of sufficient annotated data. Traditional fine-tuning of pre-trained models using only a few target samples can cause over-fitting. This can be quite limiting as most languages in the world are under-resourced. In this work, we investigate cross-lingual adaptation using a simple nearest neighbor few-shot (<15 samples) inference technique for classification tasks. We experiment using a total of 16 distinct languages across two NLP tasks- XNLI and PAWS-X. Our approach consistently improves traditional fine-tuning using only a handful of labeled samples in target locales. We also demonstrate its generalization capability across tasks.