UXLA: A Robust Unsupervised Data Augmentation Framework for Zero-Resouce Cross-Lingual NLP
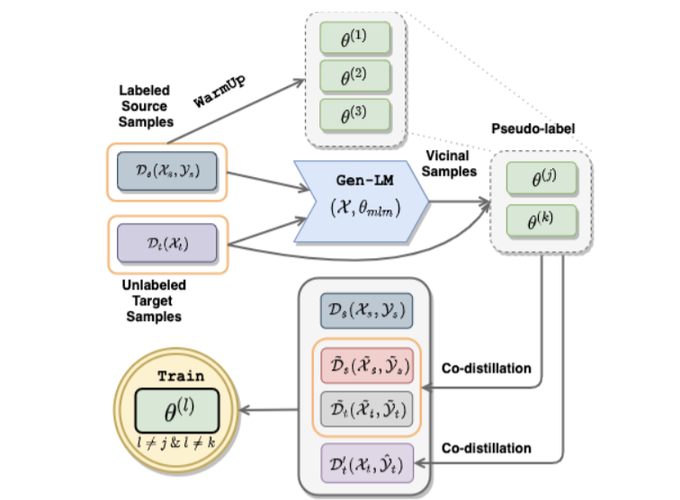 Image credit: [Augvic]()
Image credit: [Augvic]()UXLA: A Robust Unsupervised Data Augmentation Framework for Zero-Resouce Cross-Lingual NLP
Abstract
Transfer learning has yielded state-of-the-art (SoTA) results in many supervised NLP tasks. However, annotated data for every target task in every target language is rare, especially for low-resource languages. We propose UXLA, a novel unsupervised data augmentation framework for zero-resource transfer learning scenarios. In particular, UXLA aims to solve cross-lingual adaptation problems from a source language task distribution to an unknown target language task distribution, assuming no training label in the target language. At its core, UXLA performs simultaneous self-training with data augmentation and unsupervised sample selection. To show its effectiveness, we conduct extensive experiments on three diverse zero-resource cross-lingual transfer tasks. UXLA achieves SoTA results in all the tasks, outperforming the baselines by a good margin. With an in-depth framework dissection, we demonstrate the cumulative contributions of different components to its success.